

La migration de données entre des référentiels hétérogènes - c'est-à-dire lorsque les bases de données source et cible appartiennent à des systèmes de gestion de base de données différents provenant de fournisseurs différents - présente plusieurs difficultés. Dans certains cas, il est possible de se connecter aux deux bases de données simultanément. Cependant, il arrive parfois que ce ne soit tout simplement pas possible. Lorsqu'ils sont confrontés à un tel dilemme, les praticiens de bases de données n'ont d'autre choix que d'alimenter les tables à partir d'un fichier dump (fichier de vidage). Navicat peut être d'une grande aide dans ce processus. L'assistant d'importation vous permet d'importer des données dans des tables/collections à partir de diverses sources, notamment CSV, TXT, XML, DBF, etc. De plus, vous pouvez enregistrer vos paramètres sous forme de profil pour une utilisation ultérieure ou pour définir des tâches d'automatisation. Dans le blog d'aujourd'hui, nous allons utiliser l'assistant d'importation Navicat pour migrer les données de la base de données PostgreSQL « dvdrental » vers une instance MySQL 8 en utilisant la version GRATUITE Navicat Premium Lite 17.
Pour ce tutoriel, nous allons alimenter la table film dans MySQL 8 en utilisant le fichier DAT de PostgreSQL. Voici la définition de la table dans le concepteur de tables :
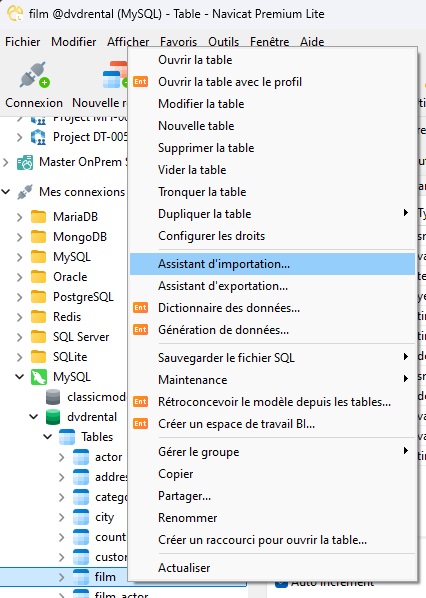
Pour lancer l'assistant d'importation, cliquez avec le bouton droit sur la table cible dans le volet de navigation Navicat (ou Ctrl-clic sous macOS) et sélectionnez « Assistant d'importation... » dans le menu contextuel :
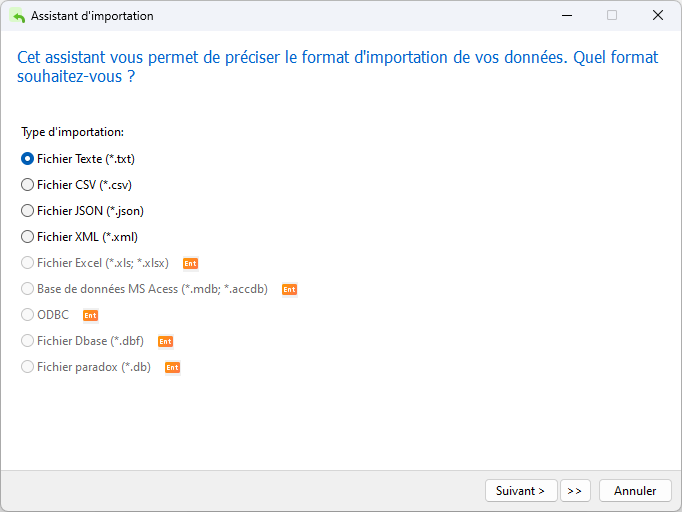
Le premier écran de l'assistant permet de sélectionner le fichier source. Notez que l'édition Lite ne prend en charge que les fichiers texte, tels que TXT, CSV, XML et JSON. Bien que nous ayons un fichier .dat, nous pouvons sélectionner l'option Fichier texte, qui englobe les formats .txt, .csv et .dat :
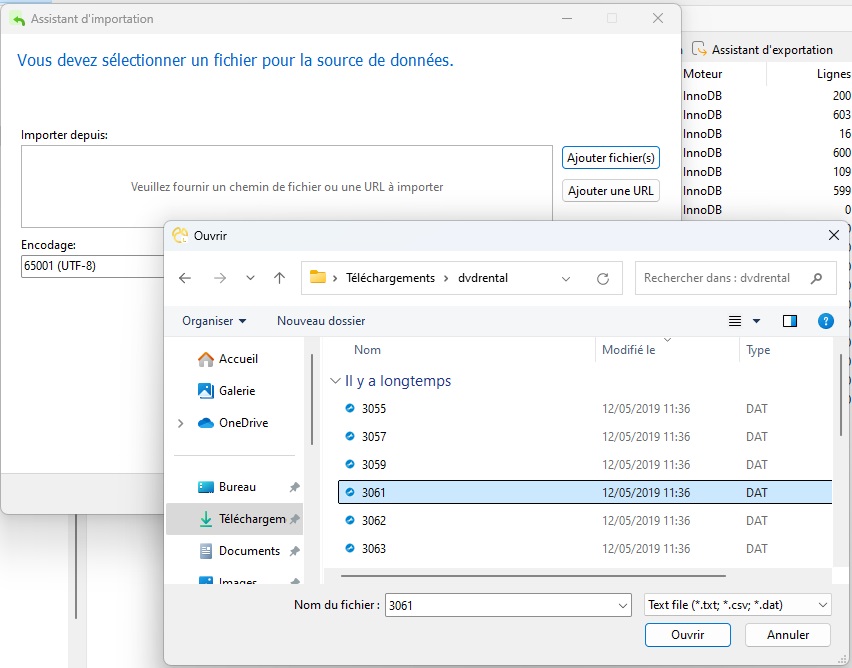
Sur l'écran suivant, nous allons choisir le fichier DAT. Il y a un fichier pour chaque table. Celui de la table de films s'appelle "3061.dat" :
Il est ensuite temps de définir les délimiteurs. Les enregistrements sont délimités à l'aide du caractère de saut de ligne (LF), tandis que les colonnes sont séparées à l'aide du caractère TAB. Il n'y a pas de guillemets autour des valeurs de texte. Veillez donc à supprimer le guillemet double (") de la zone de texte “Qualificateur de texte” :
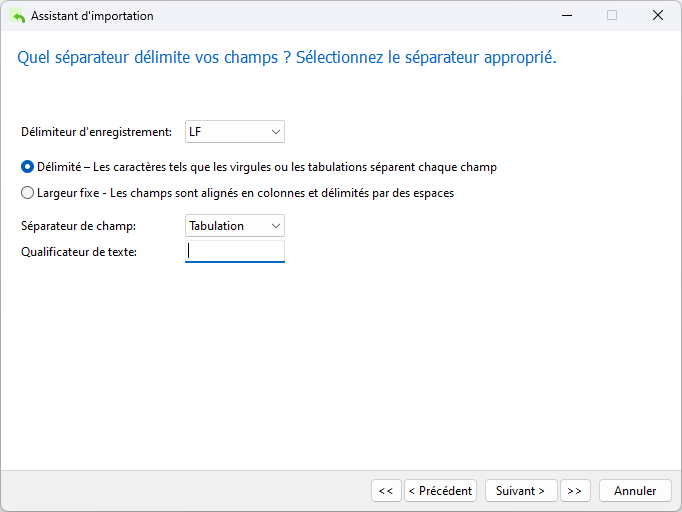
Sur l'écran suivant, vous trouverez quelques options supplémentaires. Ici, nous devons décocher la case « Ligne de nom de champ » car le fichier DAT n'inclut pas les noms de champ. Nous devrons également modifier l'ordre des dates en Année/Mois/Jour (« YMD ») et remplacer le délimiteur barre oblique (/) par le tiret (-) car les dates que nous allons importer sont au format AAAA-MM-JJ hh:mm:ss.ms, c'est-à-dire 2013-05-26 14:50:58.951 :
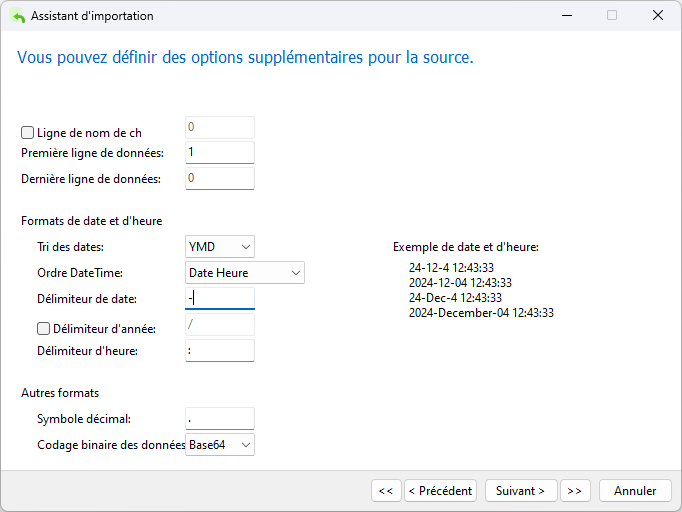
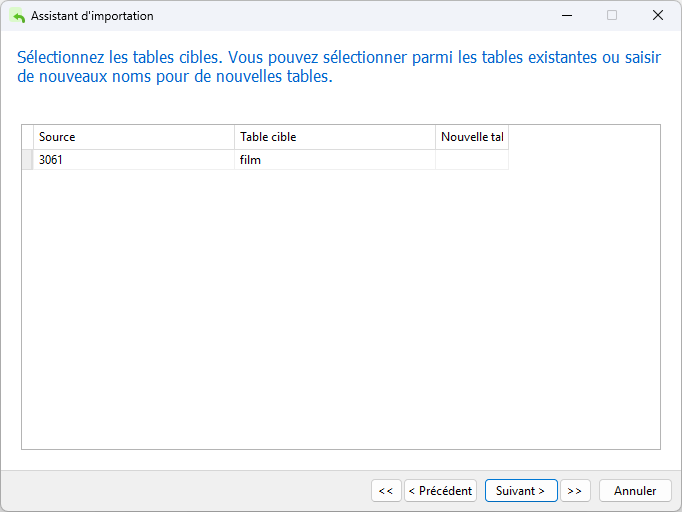
Nous avons la possibilité de choisir une table existante ou d'en créer une nouvelle. Étant donné que nous avons sélectionné la table cible lors du lancement de l'Assistant d'importation, elle devrait s'afficher ici :
L'étape suivante consiste à mapper les champs source à ceux de la table de destination. Ici, nous ne devons pas nous contenter de supposer qu'ils vont s'aligner. Un rapide coup d'œil sur une entrée du fichier DAT révèle que les colonnes last_update et special_features sont inversées :
5 African Egg A Fast-Paced Documentary of a Pastry Chef And a Dentist who must Pursue a Forensic Psychologist in The Gulf of Mexico 2006 1 6 2.99 130 22.99 G 2013-05-26 14:50:58.951 {"Deleted Scenes"} 'african':1 'chef':11 'dentist':14 'documentari':7 'egg':2 'fast':5 'fast-pac':4 'forens':19 'gulf':23 'mexico':25 'must':16 'pace':6 'pastri':10 'psychologist':20 'pursu':17
Nous pouvons cliquer avec le bouton droit (ou Ctrl-Clic sous macOS) n'importe où dans la boîte de dialogue et sélectionner « Correspondance directe avec tout » dans le menu contextuel pour mapper rapidement le champ à ceux de la table cible. Cependant, une fois cela fait, nous devons choisir manuellement les colonnes last_update et special_features dans les menus déroulants du champ Cible pour modifier leur ordre :
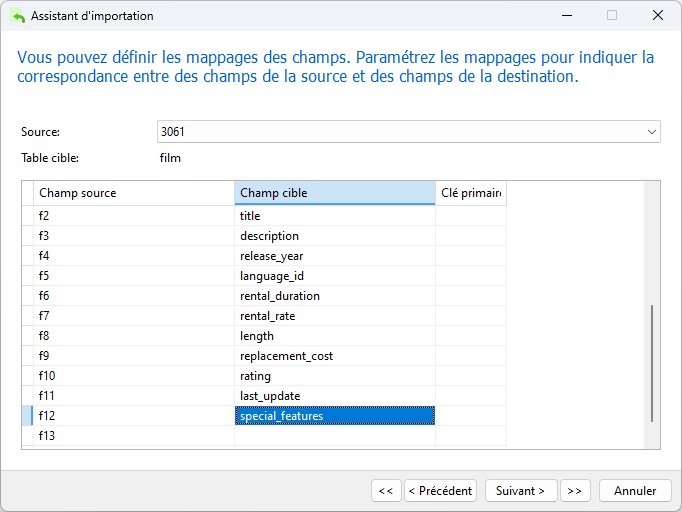
Notez que le champ 13 (f13) peut être ignoré en toute sécurité.
Pour le mode d'importation, nous pouvons soit ajouter, soit copier les enregistrements, puisque la table doit être vide :
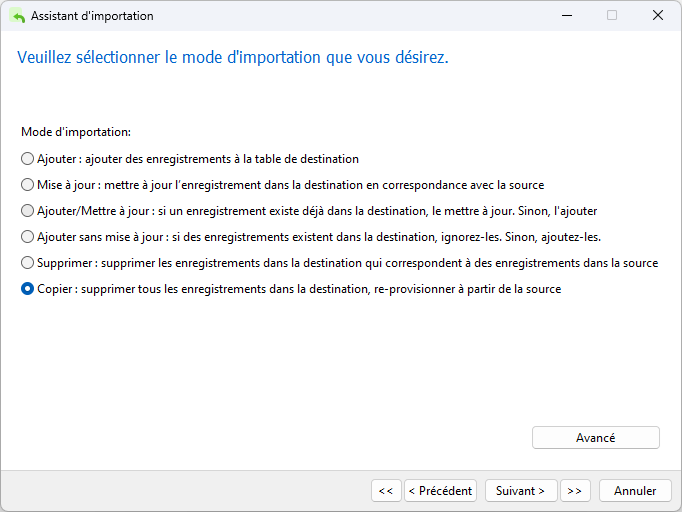
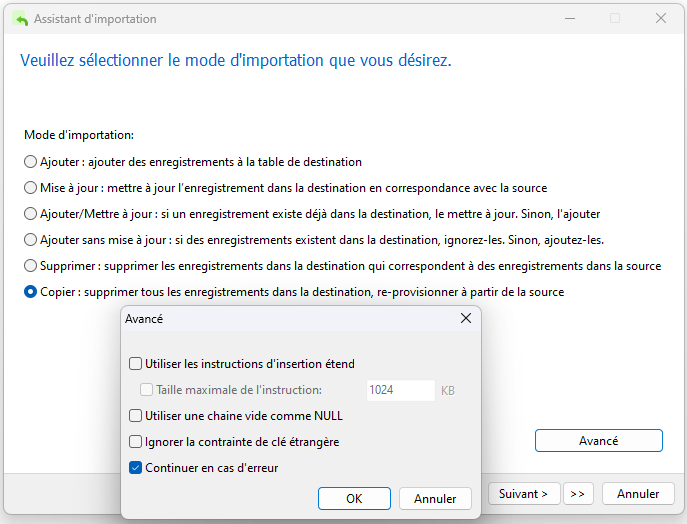
Lors de la migration d'un type de base de données vers un autre, il existe un risque élevé de rencontrer des erreurs de conversion de données. C'est pourquoi il est conseillé de décocher la case « Utiliser les instructions d'insertion étendues ». Navicat émettra alors des instructions INSERT distinctes pour chaque enregistrement au lieu de combiner plusieurs lignes en utilisant une syntaxe telle que :
INSERT INTO `film` VALUES (1, 'African Egg', 'A Fast-Paced...'), (2, 'Rumble Royale', 'A historical drama...'), (3, 'Catherine the Great', 'A new take on...'), etc...
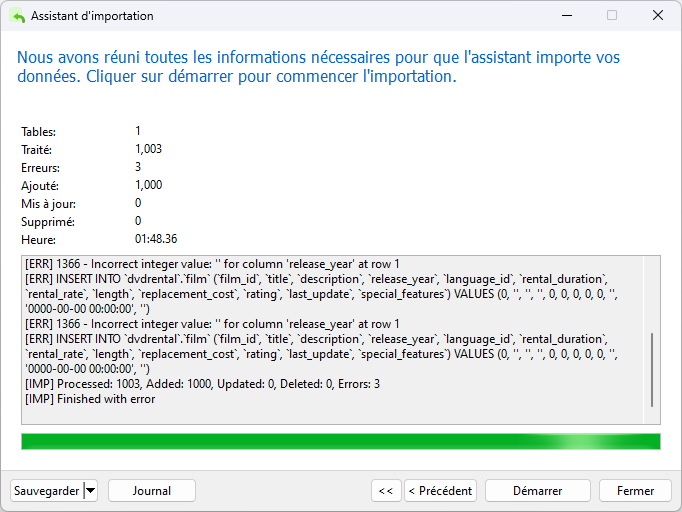
Il est maintenant temps d'appuyer sur le bouton Démarrer pour lancer le processus d'importation.
Comme prévu, il y a eu quelques erreurs (3 pour être exact), mais 1000 des 1003 lignes ont été ajoutées à la table cible !
Conclusion
L'assistant d'importation de Navicat peut réduire considérablement le temps consacré à la migration des données entre des référentiels hétérogènes. Il prend en charge une large gamme d'entrées, notamment CSV, TXT, XML, DBF, les sources de données ODBC et plus encore.
Vous souhaitez essayer Navicat Premium Lite 17 ? Vous pouvez le télécharger gratuitement ici. Il est disponible pour les systèmes d'exploitation Windows, macOS et Linux.




