

Dans Navicat BI, les sources de données font référence à des tables dans vos connexions ou des données dans des fichiers/sources ODBC et peuvent sélectionner des données à partir de tables sur différents types de serveurs. Les champs du jeu de données peuvent être utilisés pour créer un graphique. En fait, lors de la création d'un graphique, vous devrez spécifier la source de données utilisée pour remplir le graphique.
Comme nous l'avons vu tout au long de cette série, les sources de données prennent en charge les types de champs personnalisés. Ceux-ci comprennent : Type-modifié, Concaténé, Mappé, Tri personnalisé et Calculé. Dans le dernier blog, nous avons vu comment utiliser les champs de tri personnalisé pour trier les données d'un graphique en fonction d'un champ de référence. Cette semaine, nous allons apprendre à définir un ordre de tri explicite. Pour ce faire, nous allons créer un graphique à barres verticales pour l'exemple de base de données gratuit « dvdrental » qui affiche la somme des recettes de location de films par mois.
Configuration de la source de données
Comme nous l'avons mentionné précédemment, notre graphique nécessitera une source de données qui récupère les données pertinentes. Créons donc une nouvelle source de données nommée « Locations par mois ».
Voici une requête que j'ai créée dans Navicat for PostgreSQL :
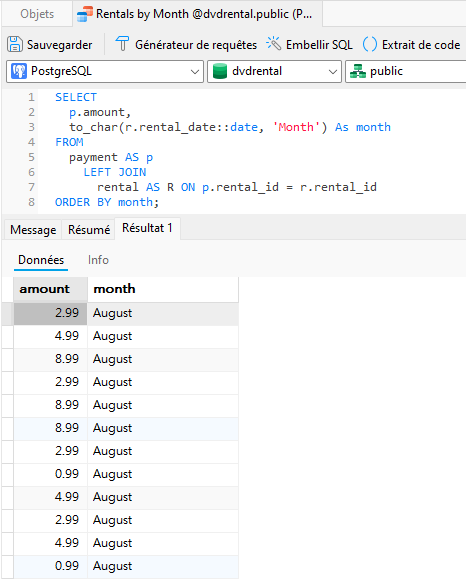
Nous pouvons maintenant l'importer dans notre source de données en cliquant sur le bouton Importer une requête :
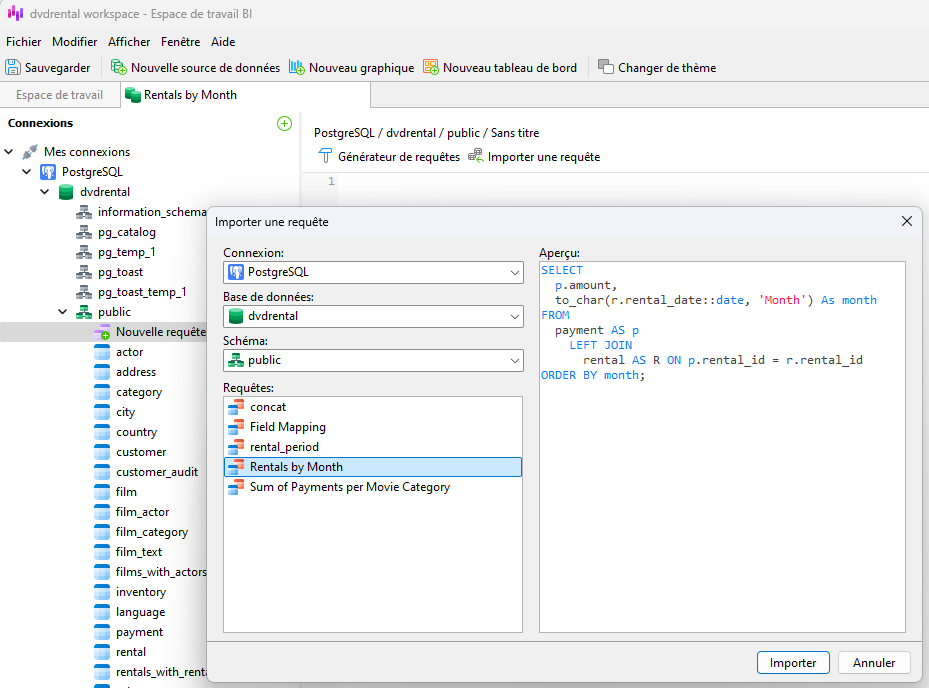
Après avoir actualisé les données, nous pouvons voir les champs de la requête et les résultats :
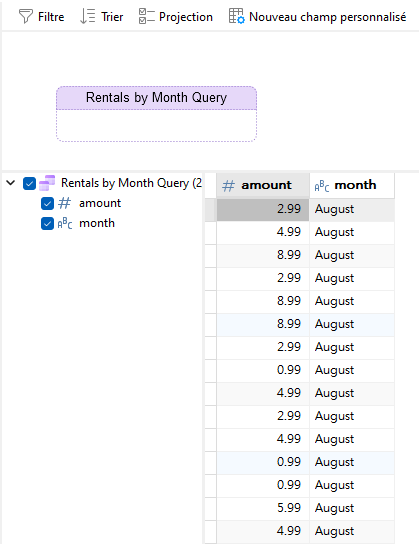
Conception du graphique des ventes par mois
Il est temps de concevoir notre graphique. Voyons d'abord ce qui se passe lorsque nous trions par nom de mois :
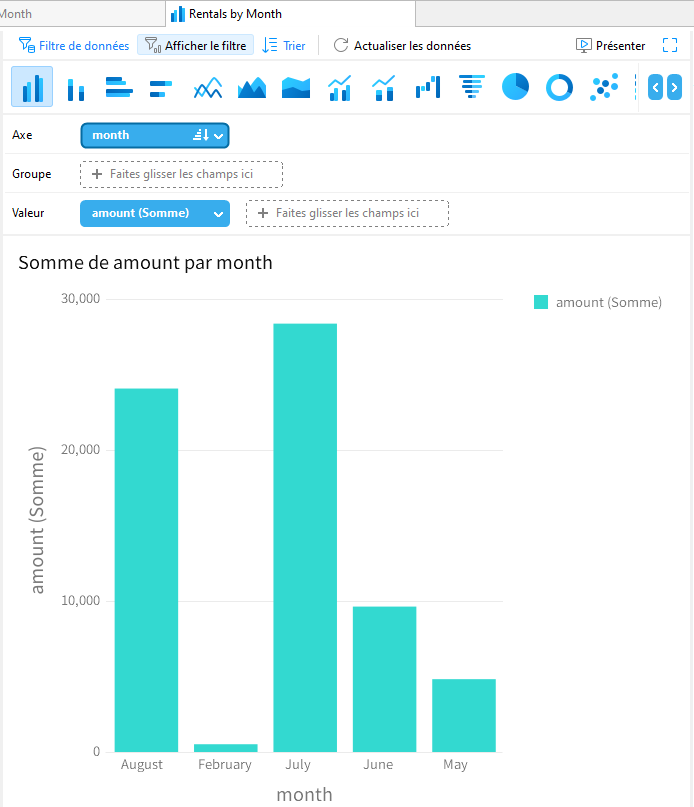
Comme vous pouvez le constater, les barres sont triées par ordre alphabétique en fonction du nom du mois, et non par ordre chronologique. Pour ce faire, nous devons ajouter un champ de tri personnalisé à la source de données en faisant un clic droit sur le mois (Control-click sur macOS) dans la liste des champs et en sélectionnant Nouveau champ personnalisé -> Nouveau champ de tri personnalisé... dans le menu contextuel :
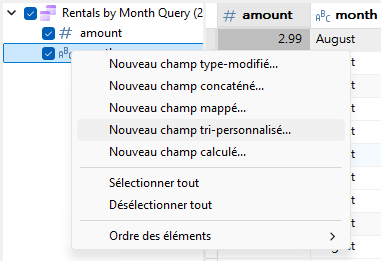
Dans la boîte de dialogue Nouveau champ de tri personnalisé, nous pouvons maintenant vérifier que le bouton radio « Personnalisé » est sélectionné et déplacer chaque mois de la liste Valeurs suggérées vers la liste Valeurs triées à l'aide du bouton fléché (surligné en rouge ci-dessous) :
Si vous vous trompez, ne vous inquiétez pas ! Vous pouvez simplement sélectionner l'élément et utiliser les flèches haut et bas pour modifier sa position dans la liste.
Lorsque vous êtes satisfait de l'ordre de tri, cliquez sur le bouton OK pour fermer la boîte de dialogue.
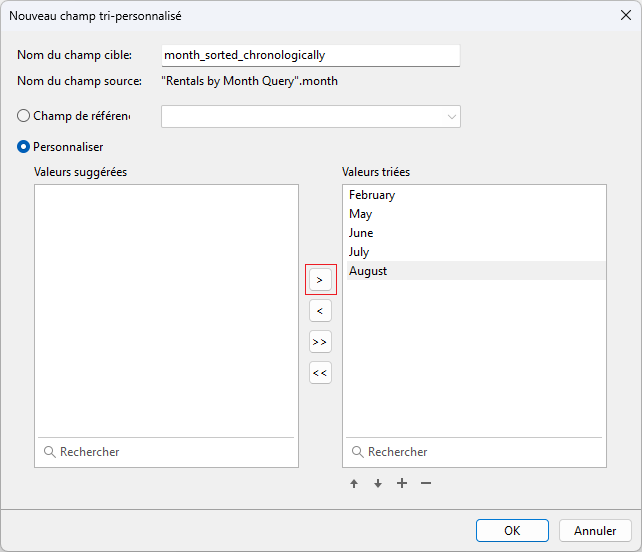
Vous devriez maintenant voir le nouveau champ Tri personnalisé dans les résultats de la requête :
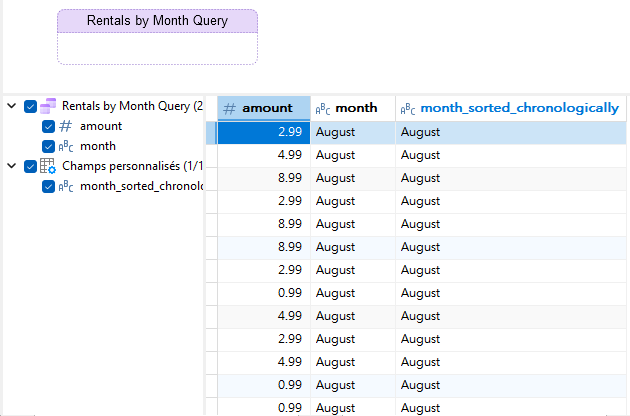
Notez que cela n'affectera pas l'ordre de tri dans la source de données. Pour cela, il faudra avoir ajouté notre nouveau champ au graphique et avoir appliqué un tri à ce dernier.
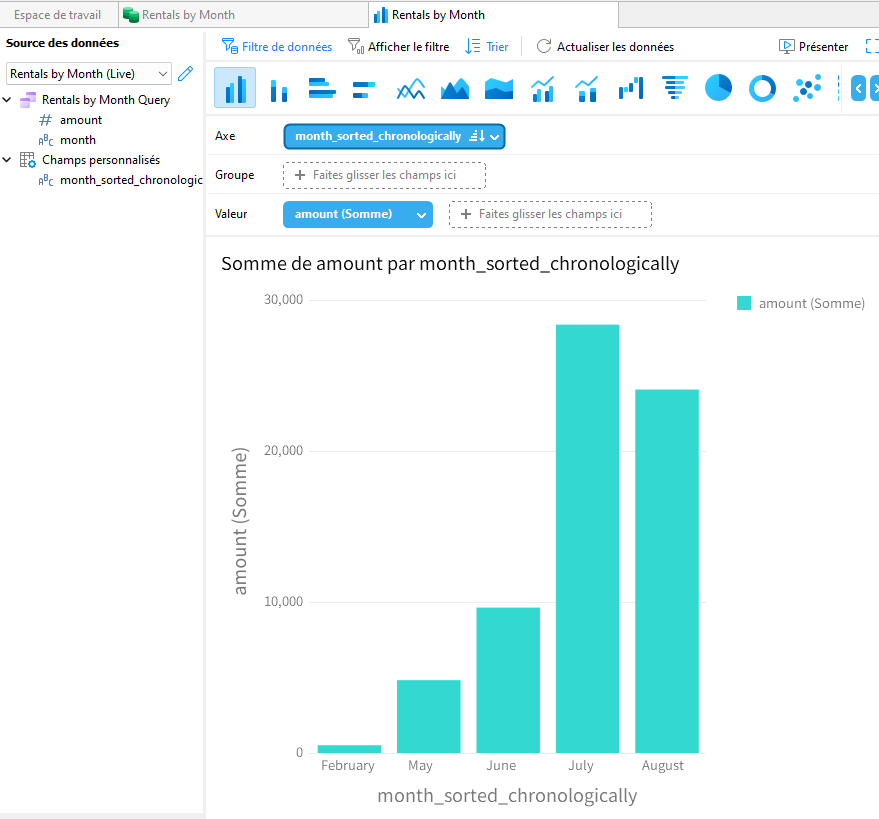
Si nous définissons maintenant le champ Tri personnalisé comme axe du graphique et que nous le trions par ordre croissant, les barres suivront l'ordre de tri que nous avons attribué dans la boîte de dialogue Nouveau champ Tri personnalisé :
Conclusion
Dans ce blog, nous avons vu comment utiliser les champs de tri personnalisé pour trier les données d'un graphique en fonction d'un ordre de tri explicite. La semaine prochaine, nous aborderons le dernier type de champ personnalisé de cette série : les champs calculés.
Vous pouvez télécharger Navicat BI pour un essai GRATUIT entièrement fonctionnel de 14 jours. Il est disponible pour les systèmes d'exploitation Windows, macOS et Linux. Vous trouverez également Navicat BI fourni avec les éditions Navicat Premium et Enterprise de Navicat pour MySQL, Oracle, PostgreSQL, SQLite, SQL Server et MariaDB.




