

Au milieu des années 90, Sun Microsystems a lancé un langage que l'on pouvait « écrire une fois, [et] exécuter partout ». Ce langage était, bien sûr, Java. Bien qu'il soit devenu l'un des langages de programmation les plus populaires à ce jour, ce slogan s'est avéré un peu optimiste. L'évolution du langage Java présente de fortes similitudes avec celle de SQL. Il peut lui aussi être porté d'une base de données à une autre, ou même d'un système d'exploitation à un autre, avec peu ou pas de modifications. Du moins, c'est ce que l'on espère. Dans le monde réel, le code de production a tendance à nécessiter quelques ajustements pour fonctionner dans un nouvel environnement. Ce blog présente quelques-unes des raisons pour lesquelles la syntaxe SQL peut différer d'un fournisseur de base de données à l'autre.
La spécification ANSI SQL
ANSI, qui signifie American National Standards Institute, définit l'ensemble des règles syntaxiques et des commandes de base à utiliser pour interagir avec les bases de données relationnelles. Toutefois, à l'instar des implémentations HTML, CSS et ECMAScript dans les navigateurs, la plupart des implémentations SQL dans les bases de données sont imparfaites et/ou incomplètes. ANSI SQL permet une certaine flexibilité dans le niveau de conformité, de sorte qu'il n'y a pas d'obligation stricte pour les fournisseurs d'implémenter l'intégralité de la spécification. . Mais même au niveau de base, le plus bas, tous les fournisseurs divergent au moins un peu.
Au-delà, il existe des extensions non standard, que tous les fournisseurs prennent en charge sous une forme ou une autre. Même quelque chose d'aussi simple que les index n'est pas standard. La spécification ANSI SQL ne dit rien sur les index, de sorte que l'implémentation de l'indexation par chaque fournisseur vient en complément à la norme. Les fournisseurs ont donc la possibilité d'utiliser la syntaxe qu'ils jugent la plus appropriée ou la plus avantageuse pour leur marque. Le résultat : une variété de dialectes SQL, qui sont en grande partie les mêmes, mais avec quelques différences.
Écrire du code SQL polyvalent
Si vous souhaitez un code SQL qui fonctionne avec tous les types de bases de données, vous devez vous en tenir aux instructions SQL standard telles que SELECT, WHERE, GROUP BY, ORDER BY, etc. Les fonctions d'agrégation telles que SUM(), AVG(), MIN() et MAX() seront également comprises par tous les types de bases de données courants, notamment SQL Server, MySQL, PostgreSQL, SQLite et Oracle. Voici une requête qui devrait fonctionner avec n'importe quelle base de données :
Select
c.customer_id,
c.customer_name,
SUM(p.amount) AS total_sales
FROM customers AS c
LEFT JOIN purchases AS p
ON c.customers_id = p.customer_id
WHERE
c.customer_location = 'Canada'
GROUP BY
c.customer_name ASC;
Apprendre le langage SQL
Si vous débutez dans l'administration et/ou le développement de bases de données, vous devriez vous concentrer sur le langage SQL qui s'appliquera au plus grand nombre possible de types de bases de données. Vous devriez également travailler avec une base de données très compatible avec ANSI SQL et très largement utilisée comme MySQL. MySQL a toujours été la base de données la plus populaire au cours des dernières décennies. Elle est également très conforme, ce qui en fait un excellent outil d'apprentissage. De nombreux articles lui sont consacrés et la plupart des exemples SQL ont été développés et exécutés sur MySQL. Microsoft SQL Server arrive en deuxième position. Cependant, ce logiciel utilise le dialecte SQL de Microsoft, appelé T-SQL. Le fait d'avoir le langage SQL le plus différent des autres plateformes fait de SQL Server une base de données de départ loin d'être idéale. Il est probablement préférable d'opter pour PostgreSQL ou SQLite, qui sont également très populaires et conformes à la norme ANSI. SQLite est particulièrement intéressant pour les novices en raison de sa petite taille et de sa portabilité.
Voici quelques-unes des différences que vous êtes susceptibles de trouver entre les bases de données :
Sensibilité à la casse
Considérons la clause WHERE name = 'Rob' Or WHERE name = 'rob' :
| MySQL | PostgreSQL | SQLite | SQL Server |
|---|---|---|---|
| Équivalent | Non equivalent | Non equivalent | Non equivalent |
Utilisation des guillemets
Certaines bases de données ne prennent en charge que les guillemets simples, tandis que d'autres autorisent les guillemets simples et doubles :
| MySQL | PostgreSQL | SQLite | SQL Server |
|---|---|---|---|
| Les deux | Simples uniquement | Les deux | Simples uniquement |
Alias de colonnes et de tables
MySQL, PostgreSQL, and SQLite all use the "AS" keyword to denote aliases, i.e., SELECT SUM(score) AS avg_score, while SQL Server employs the equals sign, i.e., SELECT SUM(score) = avg_score.
Fonctions de date et d'heure
Chaque base de données implémente ses propres fonctions de date et d'heure :
| MySQL | PostgreSQL | SQLite | SQL Server |
|---|---|---|---|
| CURDATE() CURTIME() EXTRACT() | CURRENT_DATE() CURRENT_TIME() EXTRACT() | DATE('now') strftime() | GETDATE() DATEPART() |
Navicat Premium : l'outil universel
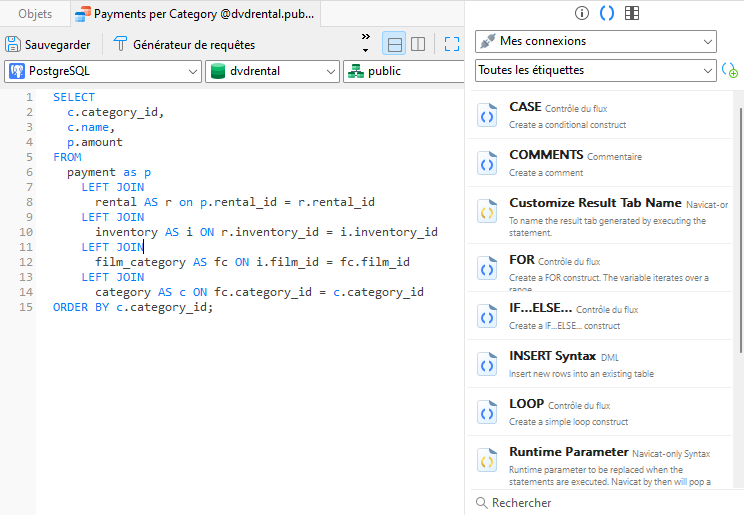
Navicat Premium est l'outil de choix pour travailler avec une grande variété de types de bases de données. Non seulement il peut se connecter à plusieurs bases de données simultanément, mais sa fonction Extraits de code (snippets) facilite plus que jamais l'écriture de requêtes sur votre type de base de données préféré. La fonction Extraits de code vous permet d'insérer du code réutilisable dans vos instructions SQL lorsque vous travaillez dans l'éditeur SQL. Outre l'accès à une collection d'extraits de code intégrés pour les instructions et les fonctions de flux de contrôle courantes, vous pouvez également définir vos propres extraits de code.
Vous pouvez télécharger Navicat 17 pour un essai GRATUIT entièrement fonctionnel de 14 jours. Il est disponible pour les systèmes d'exploitation Windows, macOS et Linux.




