

Bienvenue dans le 3ème volet de cette série sur la création de champs personnalisés dans Navicat BI. Dans la première partie, nous avons appris à ajouter des champs type-modifié à vos graphiques Navicat BI. La deuxième partie a décrit comment utiliser les champs concaténés. Le blog d'aujourd'hui présentera les champs mappés. Nous allons modifier la source de données que nous avons utilisée dans les deux derniers articles, qui se connecte à la base de données d'exemple gratuite « dvdrental » et renvoie une liste de locations pour chaque catégorie de film. Dans le prochain blog, nous utiliserons la source de données mise à jour pour créer un graphique qui compare les dernières sorties à d'autres catégories.
Présentation du mappage de champs
À bien des égards, le mappage de champs est très similaire au processus de transformation en technologie de l'information. Alors que ce dernier fait passer une valeur par un algorithme pour obtenir une valeur transformée, le mappage de champs consiste simplement à remplacer une ou plusieurs valeurs de colonnes par une autre.
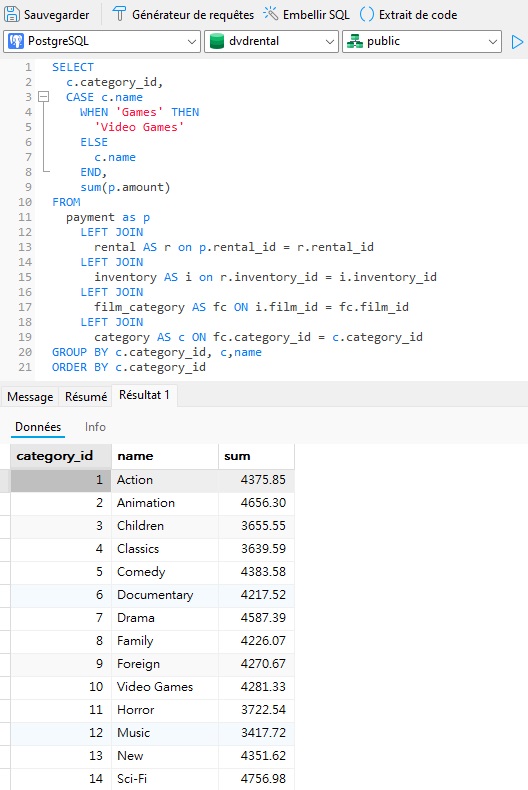
Le mappage de champs peut parfois être observé dans la liste des champs des clauses des requêtes SELECT. Par exemple, la requête « Somme des paiements par catégorie de film », qui était la source de données tout au long de cette série, renvoie une liste de catégories de films ainsi qu'une somme de leurs ventes (ou, plus précisément, de leurs locations). Nous pouvons utiliser une instruction CASE pour rendre certains noms de catégories plus descriptifs, comme par exemple « Jeux » en « Jeux vidéo » :
Création de la source de données Dernières sorties versus Autres catégories
Avant de concevoir un graphique, nous avons besoin d'une source de données pour récupérer les informations dont nous avons besoin. Une fois que vous aurez quelques sources de données, vous trouverez peut-être plus facile de réutiliser une source existante plutôt que d'en créer une nouvelle à partir de zéro. En fait, la source de données Locations par catégorie que nous avons utilisée la dernière fois fera parfaitement l'affaire.
Nous pouvons facilement dupliquer n'importe quel élément dans l'espace de travail de Navicat BI en le sélectionnant et en faisant un clic droit (ou Control-click sur macOS) dans l'espace de travail, et en sélectionnant Dupliquer
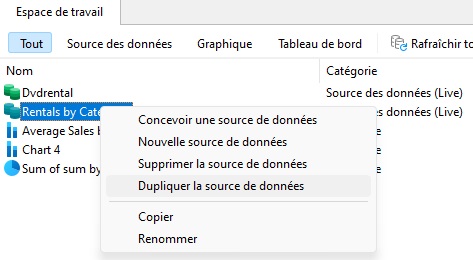
Cela créera une nouvelle source de données nommée « Locations par catégorie 1 ». Pour renommer notre nouvelle source de données, cliquez une fois sur l'élément pour le sélectionner, puis une deuxième fois pour activer le mode édition. Vous pouvez savoir que l'élément est prêt à être modifié lorsque l'étiquette se transforme en zone de texte avec le texte de l'élément surligné en bleu :
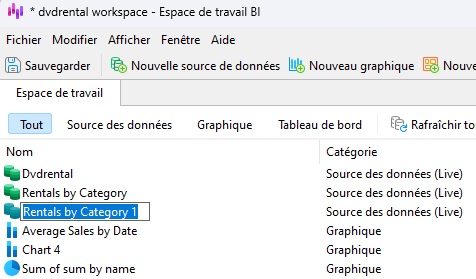
Appelons notre nouvelle source de données « Dernières sorties versus Autres catégories ». Appuyez sur la touche Entrée pour enregistrer le nouveau nom :
Ajout d'un champ mappé
Pour ajouter un nouveau champ mappé à la source de données, cliquez avec le bouton droit de la souris sur le champ de nom (ou cliquez en maintenant la touche Contrôle enfoncée sur macOS) et sélectionnez Nouveau champ mappé... dans le menu contextuel :
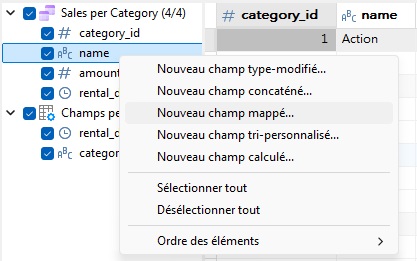
Cela ouvre la boîte de dialogue Nouveau champ mappé. Commençons par renommer le nom du champ cible en « mapped_category_names ».
Ensuite, nous allons mapper le nom de catégorie "Nouveau" en quelque chose de plus descriptif. Pour ce faire, procédez comme suit :
- Étant donné que la catégorie « Nouveau » aura un mappage un à un avec la nouvelle valeur, sélectionnez « Un à un » dans la liste déroulante Méthode de mappage.
- Choisissez « Nouveau » comme valeur source.
- Saisissez « Dernière sortie » pour la valeur mappée.
Nous allons maintenant répéter le processus pour les valeurs nulles, c'est-à-dire les films auxquels aucune catégorie n'a été attribuée.
- Cliquez sur le bouton Ajouter et sélectionnez « Ajouter des valeurs un à un » dans le menu contextuel.
- Dans la boîte de dialogue Ajouter des valeurs un à un, cochez la case à côté de la valeur (NULL) et saisissez « Non catégorisé » pour la valeur mappée.
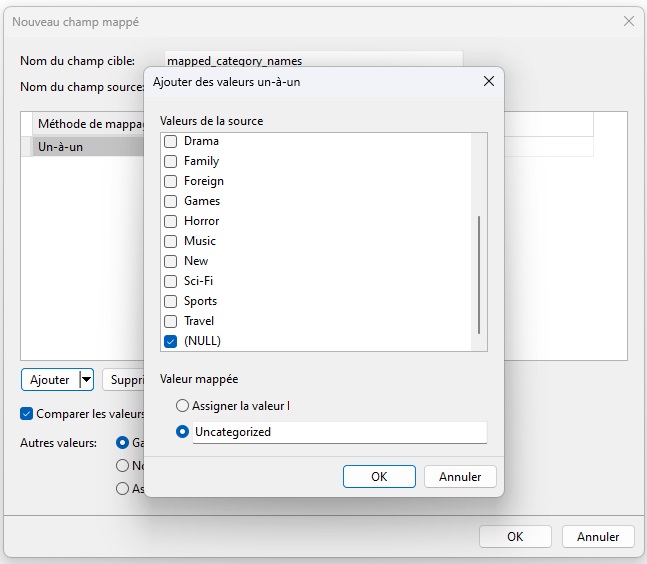
- Cliquez sur le bouton OK pour fermer la boîte de dialogue et ajouter la nouvelle ligne à la table Champs mappés.
Enfin, activez la case d'option Nouvelle valeur à côté de l'étiquette Autres valeurs et saisissez « Autres catégories » afin que toutes les autres valeurs soient affectées à cette catégorie fourre-tout. À ce stade, la boîte de dialogue doit se présenter comme suit :
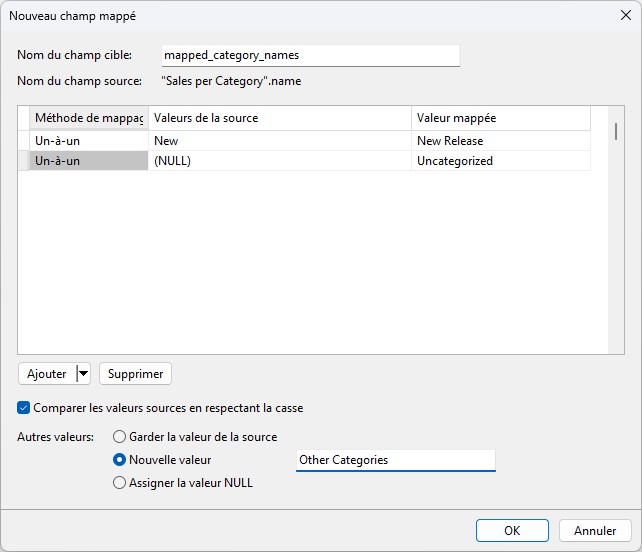
Cliquez sur OK pour fermer la boîte de dialogue. Vous devriez maintenant voir le champ mapped_category_names dans la grille de données :
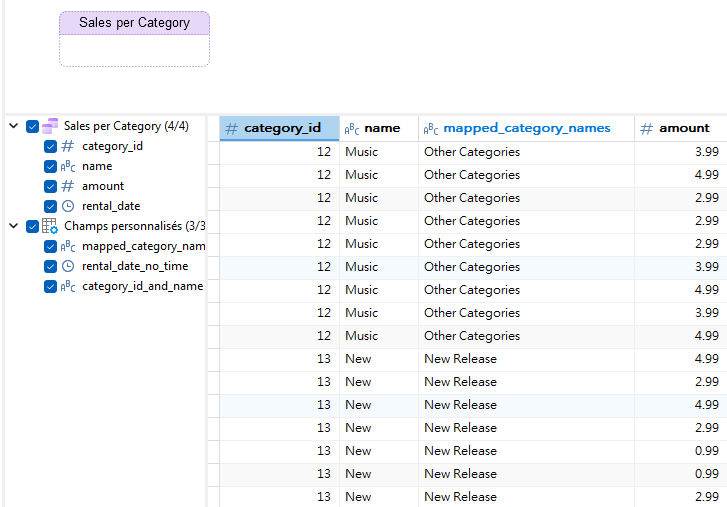
Si vous le souhaitez, vous pouvez supprimer les autres champs calculés (comme indiqué dans l'image ci-dessus), car ils ne seront pas nécessaires pour le graphique que nous créerons la semaine prochaine.
Conclusion
Ce blog explique comment utiliser les champs mappés dans vos sources de données Navicat BI. Il s'agit de l'un des cinq types de champs personnalisés, qui incluent : Type modifié, Concaténé, Mappé, Tri personnalisé et Calculé. La semaine prochaine, nous utiliserons la source de données « Dernières sorties versus Autres catégories » pour créer un graphique qui compare les dernières sorties aux autres catégories.
Vous pouvez télécharger Navicat BI pour un essai GRATUIT entièrement fonctionnel de 14 jours. Il est disponible pour les systèmes d'exploitation Windows, macOS et Linux.





