

Le blog de la semaine dernière annonçait le lancement prochain de Navicat 17 (édition anglaise), qui est actuellement en version bêta et devrait arriver le 13 mai ! Comme nous l'avons vu, la version 17 introduit de nombreuses nouvelles fonctionnalités intéressantes. L’une des plus importantes est l’outil de profilage des données. Il offre une représentation visuelle et complète de vos données en un clic ! Dans le blog d'aujourd'hui, nous l'utiliserons pour obtenir quelques statistiques rapides sur la table de location de l'exemple de base de données gratuit PostgreSQL "dvdrental" sample database.
Lancement de l'outil de profilage des données
Comme mentionné dans l'introduction, l'outil de profilage des données ne nécessite guère plus qu'un clic sur un bouton pour être utilisé. Vous le trouverez dans la barre d'outils de n'importe quelle table, vue ou résultat de requête (surligné en rouge ci-dessous) :
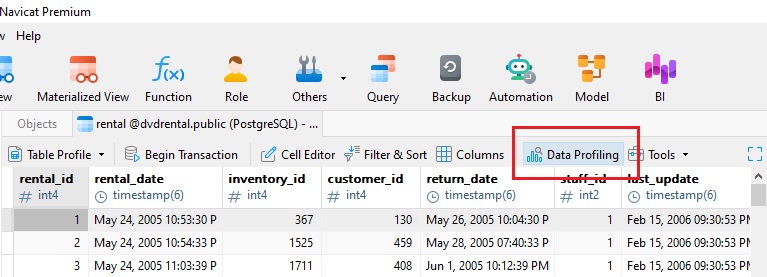
À partir de là, vous pouvez choisir de profiler tous les enregistrements (valeur par défaut) ou d'ajouter un filtre pour profiler uniquement les lignes qui correspondent à un critère donné :
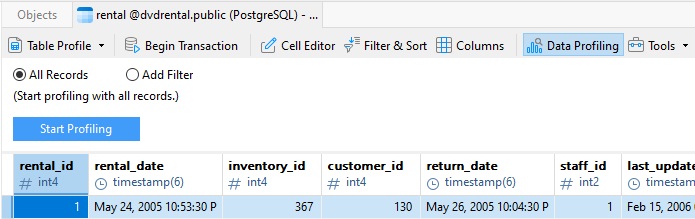
Filtrage des enregistrements
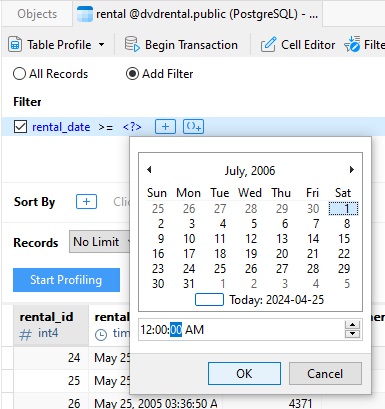
Pour les ensembles de données comportant de nombreux enregistrements, il est souvent utile de se concentrer sur un sous-ensemble de données. C'est là qu'intervient l'option « Add filter ». Elle nous permet d'ajouter des filtres (et de trier) à l'aide de la fonction familière « Filter & Sort”. Disons que nous souhaitons uniquement profiler les enregistrements de la table de location dont la date de location se situe dans la première moitié de 2006. Tout ce que nous avons à faire est d'ajouter un filtre sur la colonne Rental_date qui sélectionne les lignes avec des valeurs comprises entre le 1er janvier 2006 et 00. :00:00 et le 30 juin 2006, à 23:59:59. La sélection des dates et des heures est un jeu d'enfant, grâce au sélecteur de date et d'heure intégré !
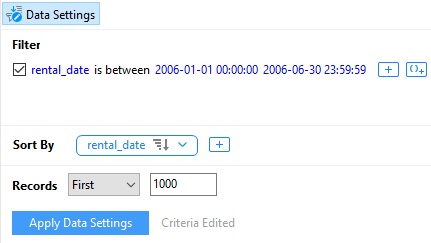
Une fonctionnalité du Data Profiler que vous ne trouverez pas dans l'outil « Filtrer et trier » est la possibilité de limiter les enregistrements à un certain nombre, par exemple mille :
Affichage des résultats de profilage
En cliquant sur le bouton « Start Profiling » ou « «Apply Data Settings » après avoir édité les critères, vous exécutez le profileur sur les lignes qui correspondent aux critères de filtrage sélectionnés. Fgb
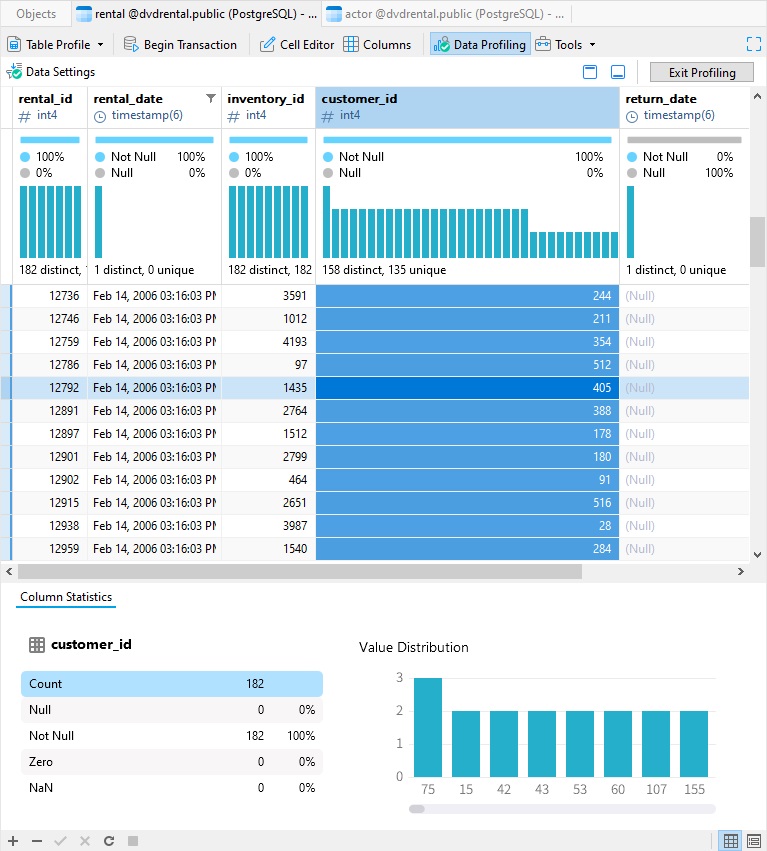
Cliquer sur l'en-tête de colonne vous permettra d’afficher les statistiques de ce champ. Celles-ci sont affichées à 2 endroits : sous le nom de la colonne et sous la grille.
Les types de statistiques que vous trouverez incluent le pourcentage de valeurs nulles par rapport aux valeurs non nulles, ainsi que le nombre de valeurs distinctes et uniques. Il existe même un tableau de répartition des valeurs ! Pour afficher toutes les valeurs, vous pouvez soit augmenter la largeur de la colonne, soit simplement utiliser la barre de défilement en bas du graphique de distribution des valeurs dans les statistiques de colonne en bas de l'écran :
Changer la mise en page
Il existe quelques options pour modifier la façon dont les données sont présentées. Par exemple, nous pouvons afficher les distributions par nombre ou par valeur :
Nous pouvons également choisir entre une mise en page compacte ou détaillée (détaillée est la valeur par défaut). Voici les en-têtes des tableaux de location avec la disposition Compact :
Afficher les détails
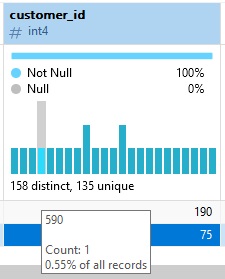
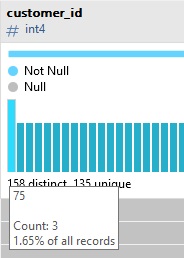
Chaque barre du diagramme de distribution représente un enregistrement réel dans la table, la vue ou la requête sous-jacente. Nous pouvons en apprendre davantage en passant le curseur dessus. La boîte de dialogue affiche la valeur, ainsi que le nombre de fois où elle apparaît dans l'ensemble de données et le pourcentage que cela représente dans tous les enregistrements :
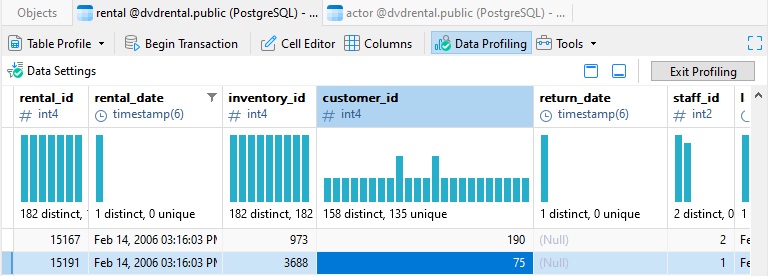
De plus, cliquer sur une barre mettra en lumière cet enregistrement, qui se situera sur cette ligne de la grille et affichera les statistiques pertinentes pour cette valeur :
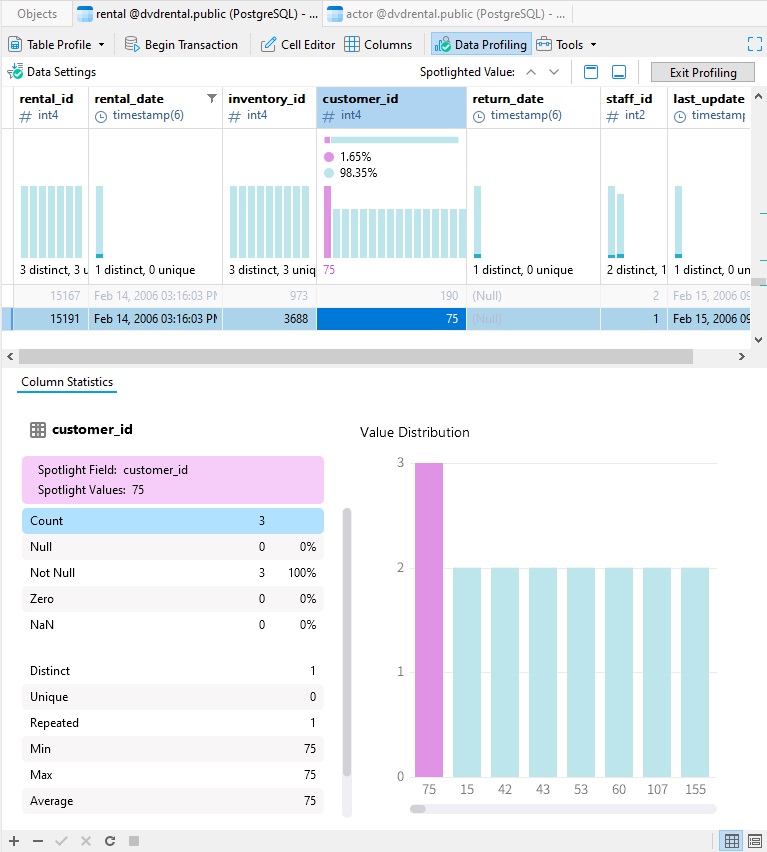
Cliquer une seconde fois sur la barre supprimera le Spotlight.
Nous pouvons également voir dans l'image ci-dessus la gamme complète des statistiques disponibles dans la section Statistiques des colonnes. Il comprend des chiffres supplémentaires, tels que le nombre de valeurs répétées, les valeurs minimales et maximales, et bien d'autres.
Conclusion
Dans le blog d'aujourd'hui, nous nous sommes familiarisés avec le nouvel outil de profilage de données de Navicat 17 en l'utilisant pour obtenir des statistiques rapides sur la table de location de la base de données exemple gratuite « dvdrental sample database ».
Le 13 mai, n'oubliez pas de visiter la page produit Navicat Premium pour en savoir plus sur la version 17 (édition anglaise) !





